Distributed Computing: Distributed System Checkpoints and it’s type-checkpoint levels its tools
Distributed Computing: Distributed System Checkpoints and it’s type-checkpoint levels its tools.
Contents
- 0.1 Distributed Computing: Checkpoints in Distributed Systems
- 0.2 What is Checkpointing in Distributed Systems?
- 0.3 Types of Checkpoints in Distributed Systems
- 0.4 Coordinated Checkpointing
- 0.5 Uncoordinated Checkpointing
- 0.6 Communication-Induced Checkpointing
- 0.7 Application-Level Checkpointing
- 0.8 Checkpoint Levels in Distributed Systems
- 0.9 Tools for Checkpointing in Distributed Systems
- 0.10 Conclusion
- 1 🧩 What is a Checkpoint in Distributed Systems?
- 2 🛠️ Purpose of Checkpointing
- 3 📊 Types of Checkpoints in Distributed Systems
- 4 🧭 Checkpointing Levels
- 5 🔄 Types of Checkpointing Techniques
- 6 🧰 Tools for Checkpointing in Distributed Systems
- 7 ⚠️ Challenges in Checkpointing
- 8 🧠 Summary
Distributed Computing: Checkpoints in Distributed Systems
What is Checkpointing in Distributed Systems?
Checkpointing is a fault-tolerance mechanism in distributed computing that periodically saves the system state. If a failure occurs, the system can restart from the last checkpoint instead of starting from scratch.
Key Idea:
Saves system state at intervals.
Reduces computation loss during failures.
Speeds up recovery in distributed systems.
Types of Checkpoints in Distributed Systems
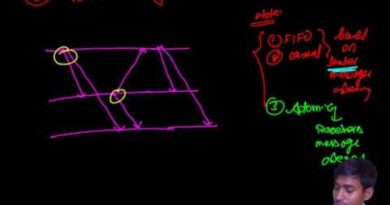
Coordinated Checkpointing
Definition: All nodes in the system synchronize and save their states together.
Ensures consistency (no orphan or lost messages).
Used in global snapshots.
Slower due to coordination overhead.
Example:
- Two-Phase Commit (2PC)
- Chandy-Lamport Algorithm
Uncoordinated Checkpointing
Definition: Each process takes checkpoints independently without synchronization.
Faster, no coordination required.
Risk of cascading rollbacks (domino effect).
Example:
- Individual process backups.
Communication-Induced Checkpointing
Definition: A hybrid approach where checkpoints are triggered based on message passing.
Prevents inconsistent states.
Avoids the domino effect from uncoordinated checkpointing.
Higher overhead due to message tracking.
Example:
- Log-based checkpointing in distributed databases.
Application-Level Checkpointing
Definition: Checkpoints are managed at the software level rather than system level.
Allows customized checkpointing in applications.
Efficient for high-performance computing (HPC).
Requires developer implementation.
Example:
- MPI (Message Passing Interface) checkpointing.
Checkpoint Levels in Distributed Systems
Process-Level Checkpointing: Saves state of individual processes.
System-Level Checkpointing: Saves the entire OS state.
Application-Level Checkpointing: Saves the state at the application level.
Tools for Checkpointing in Distributed Systems
1. DMTCP (Distributed MultiThreaded Checkpointing)
- Application-level checkpointing.
- Supports parallel computing systems.
2. CRIU (Checkpoint/Restore in Userspace)
- Process-level checkpointing for Linux.
- Saves process state & resumes execution.
3. BLCR (Berkeley Lab Checkpoint/Restart)
- Kernel-level checkpointing for HPC systems.
- Works with MPI applications.
4. Hadoop Checkpointing
- Used in HDFS (Hadoop Distributed File System) for fault tolerance.
Conclusion
Checkpointing reduces system failures’ impact by allowing recovery from saved states. Different types & tools are used based on the system requirements (speed, reliability, and overhead).
Would you like code examples or real-world use cases?
Distributed Computing involves multiple computer systems working together to achieve a common goal. One key challenge in such systems is ensuring fault tolerance, which is where checkpoints come in.
🧩 What is a Checkpoint in Distributed Systems?
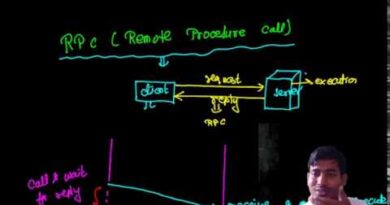
A checkpoint is a saved state of a process or the entire system at a specific point in time. If a failure occurs, the system can roll back to the last checkpoint rather than starting over.
🛠️ Purpose of Checkpointing
-
Fault Tolerance
-
Failure Recovery
-
Performance Optimization
-
Minimizing Downtime
📊 Types of Checkpoints in Distributed Systems
1. Local Checkpoints
-
Each process independently saves its state.
-
Simple but inconsistent: may lead to domino effect (rollback cascades).
2. Global Checkpoints
-
A set of local checkpoints, one per process, such that the combination represents a consistent global state.
-
Used in coordinated checkpointing.
🧭 Checkpointing Levels
| Level | Description | Use Case |
|---|---|---|
| Application-level | App explicitly saves state | Custom control, efficient for app-specific logic |
| Library-level | Uses a library (like BLCR) | Transparent to app, often used in HPC |
| System-level | OS or VM-level snapshots | No modification to app, broader but heavier |
| Hardware-level | Hardware saves memory states | Fastest, but rare and hardware-dependent |
🔄 Types of Checkpointing Techniques
✅ 1. Coordinated Checkpointing
-
All processes agree to take checkpoints at the same time.
-
Avoids inconsistency but can delay execution due to synchronization.
✅ 2. Uncoordinated Checkpointing
-
Processes checkpoint independently.
-
Prone to domino effect, but simpler implementation.
✅ 3. Communication-Induced Checkpointing
-
Checkpoints are taken based on message passing behavior.
-
Tries to ensure consistency without full coordination.
🧰 Tools for Checkpointing in Distributed Systems
| Tool/Library | Description |
|---|---|
| BLCR (Berkeley Lab Checkpoint/Restart) | Kernel-level checkpointing for Linux |
| CRIU (Checkpoint/Restore In Userspace) | Linux tool to freeze running apps and store state |
| DMTCP (Distributed MultiThreaded CheckPointing) | Transparent user-level checkpointing for distributed and multi-threaded apps |
| OpenMPI Checkpointing | MPI-based applications using BLCR for fault tolerance |
| LAM/MPI | Supports checkpoint/restart via coordination in MPI apps |
| Docker Checkpoint/Restore | Uses CRIU under the hood to checkpoint containers |
⚠️ Challenges in Checkpointing
-
Overhead of taking and storing checkpoints.
-
Consistency across distributed components.
-
Handling message replays, open files, and network connections.
-
Storage and management of checkpoint data.
🧠 Summary
Checkpointing is a critical technique in distributed systems for ensuring reliability and resilience. Depending on the application’s complexity and requirements, different checkpointing strategies and tools can be used.
Would you like a diagram to visualize checkpointing, or help implementing one in code or a cloud platform (like Kubernetes)?